What are we talking about when we talk about consistency in DynamoDB
Start
DynamoDB is so popular in the AWS family. Everyone who doesn't use DynamoDB wants to launch it, everyone who is using DynamoDB wants to abandon it :p
Let's see what DynamoDB can do, what can't do, and what couldn't do before but can do now.
ACID vs BASE
ACID model is widely used in relational databases. It keeps strong serializability for the database so that the database is considered as a whole to the application.
Compared to ACID, the BASE model is a trade-off of consistency with all other stuff that the application cares about, like the availability, data format, or latency. That means the application needs to handle or ignore the downgrade of consistency to gain the improvements of some aspects.
ACID Model
- Atomic – Each transaction is either properly carried out or the process halts and the database reverts back to the state before the transaction started. This ensures that all data in the database is valid.
- Consistent – A processed transaction will never endanger the structural integrity of the database.
- Isolated – Transactions cannot compromise the integrity of other transactions by interacting with them while they are still in progress.
- Durable – The data related to the completed transaction will persist even in the cases of network or power outages. If a transaction fails, it will not impact the manipulated data.
Database samples: MySQL, PostgreSQL, Oracle, SQLite, and Microsoft SQL Server, DB2.
BASE Model
- Basically Available – Rather than enforcing immediate consistency, BASE-modelled NoSQL databases will ensure the availability of data by spreading and replicating it across the nodes of the database cluster.
- Soft State – Due to the lack of immediate consistency, data values may change over time. The BASE model breaks off with the concept of a database which enforces its own consistency, delegating that responsibility to developers.
- Eventually Consistent – The fact that BASE does not enforce immediate consistency does not mean that it never achieves it. However, until it does, data reads are still possible (even though they might not reflect reality).
Database samples: MongoDB, Cassandra, Redis, Couchbase, DynamoDB.
DynamoDB Data Model
DynamoDB is key-value storage, though it is a little bit different from other k-v storage like Redis.
From a comparative standpoint, a row in Amazon DynamoDB is referred to as an item, and each item can have any number of attributes. An attribute comprises a key and a value and commonly referred to as a name-value pair. An Amazon DynamoDB table can have unlimited items indexed by primary key.
Amazon DynamoDB defines two types of primary keys: a simple primary key with one attribute called a partition key and a composite primary key with two attributes. A primary key is the hash key for consistent hashing. The composite key is the key to query in the specified partition note. Besides the key, DynamoDB also supports the index. The whole data model is similar to Cassandra(except Cassandra is using Column Family) with detailed differences.
With this data model, DynamoDB is a truly distributed NoSql database compared to other relational databases like MySQL which has only one primary storage. There are more details for the DynamoDB data model here
DynamoDB Consistency Model
From the previous session, we know that the data in DynamoDB is split into each partition. Now let's talk about the consistency model in DynamoDB.
Because the DynamoDB is a black box, so most of the information of AWS products is from papers or tests. In short, DynamoDB is an eventually consistency NoSQL database as in the BASEmodel, though from the AWS documents, it can becomestrong consistencytoo. So what is astrong consistency, is it similar to the serializability` from the RDMS?
To answer this question, first we need to know the serializability model in a distributed system.
Why Consistency is HARD in a Distributed Database?
To answer this question, we need to understand the serializable model first. We won't talk too deep since it can take days to get it clear. Instead we will only demystify the concept in a distributed database so that we can have the basic understanding to answer the question.
When we talk about transaction in a traditional RDMS, we often assume the ACID is guaranteed by the transaction. In fact it is not. The transaction has nothing to do with consistency, but about atomic and isolation.
Consistency ensures that a transaction can only bring the database from one valid state to another, it makes sure the state set at any given time is valid.
Let's loop back to the serializable model.
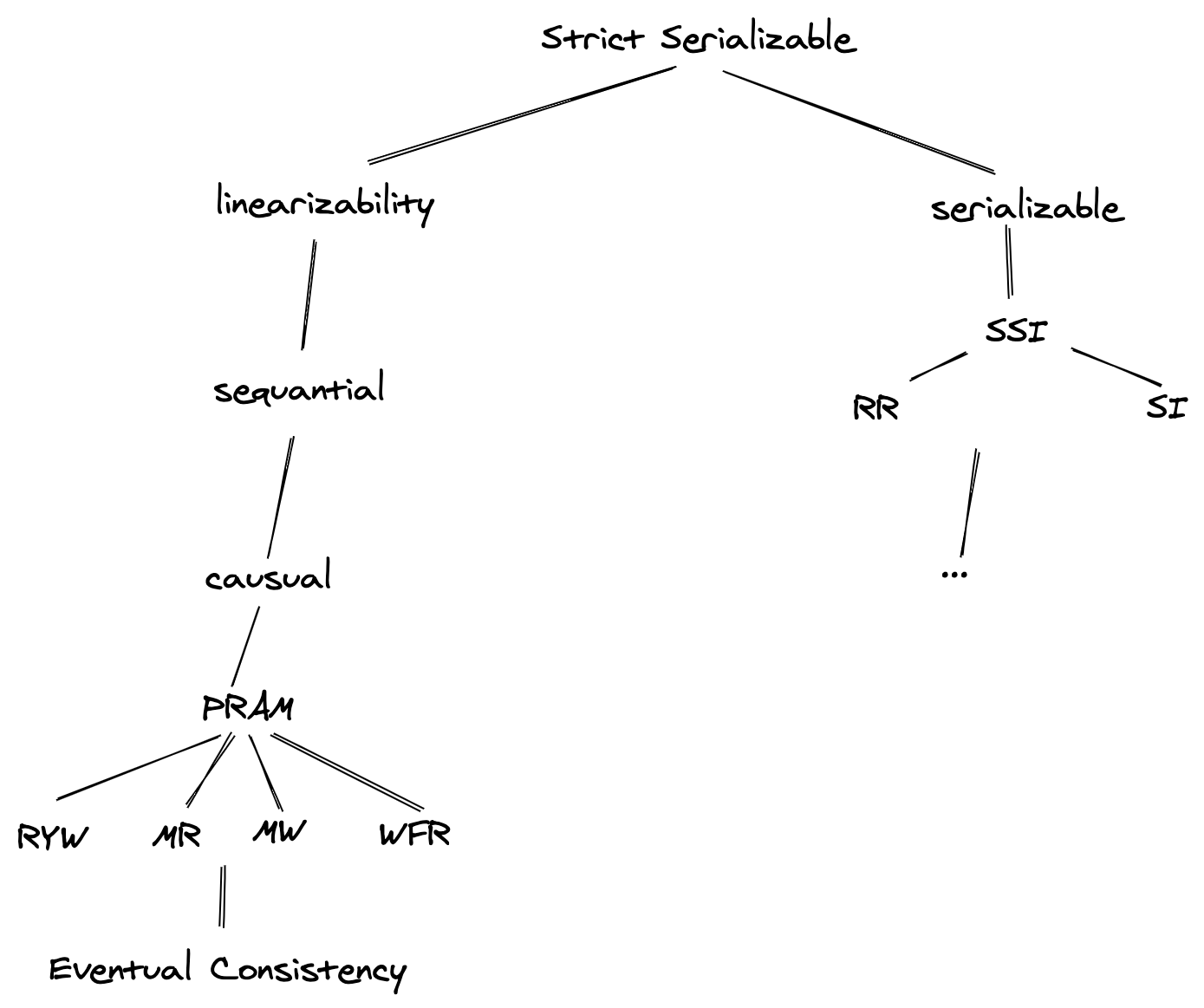
From the image above, the strong serializable is from two-part in the tree above, the right part is the serializable model, like the isolation level we are familiar with in a database. The left part is the consistency level, in a traditional database, we are using some methods like locks or point-in-time view like optimized/pessimistic locks, MVCC, etc. The methods are widely used in traditional RDMS like MySQL, though not in NewSQL like DynamoDB, why?
Because the cost is so huge. No matter which consistency algorithm in RDMS, there always needs locks no matter what is the lock type. Compared to a single primary, the cost in a distributed system of maintaining a lock is so huge, it cannot scale for such an algorithm like 2PC, then it will lose the meaning of a distributed system.
But wait! DynamoDB provides eventual consistency and strong consistency. Does strong consistency the same as RDMS consistency? Now let's see the consistency level in DynamoDB.
Consistency in DynamoDB
DynamoDB is using the Gossip distributed algorithm to make the eventual consistency, the paper can be found here. This algorithm uses quorum to make a flexible consistency model.
A quorum is the minimum number of votes that a distributed transaction has to obtain in order to be allowed to perform an operation in a distributed system. A quorum-based technique is implemented to enforce consistent operation in a distributed system.
In a strong consistency in DynamoDB, it means Rr + Wr > Tr, Rr means the read replica factor, Wr means the write replica factor, Tr means the total replica factors. The formula is simple, make sure the majority of nodes have a consistent response for each operation. Usually Rr = Wr = Tr/2 + 1.
Note: the paper uses a Vector Clock as the timestamp for each item, though in real-world implementation, it replaced by Last Write Wins(LWW) because of performance issues. The DynamoDB global table is using LWW as well. According to this article the DynamoDB in one region probably uses LWW as well.
Isolation with Quorum?
As we discussed above, the quorum is a consistency model which has nothing to do with isolation. It only applies to a single item.
Consistency with Quorum?
Can the quorum model map to the sequential in RDMS? The answer is - no. Based on the concept of the consistency model, the Read in a sequential model should get the latest writes which happened before it. So is the casual model.
The strong consistency model is under Session Guarantees which will make sure the consistency is sequential in a specified session -
- Read Your Writes: If a process performs a write, the same process later observes the result of its write.
- Monotonic Reads: The set of writes observed (read) by a process is guaranteed to be monotonically non-decreasing.
- Monotonic Writes: If some process performs a write, followed sometime later by another write, other processes will observe them in the same order.
- Write Follow Reads - Respect Causality: If some process performs a read followed by a write, and another process observes the result of the write, then it can also observe the read (unless it has been overwritten).
Easter Egg - Dynamo Transactions
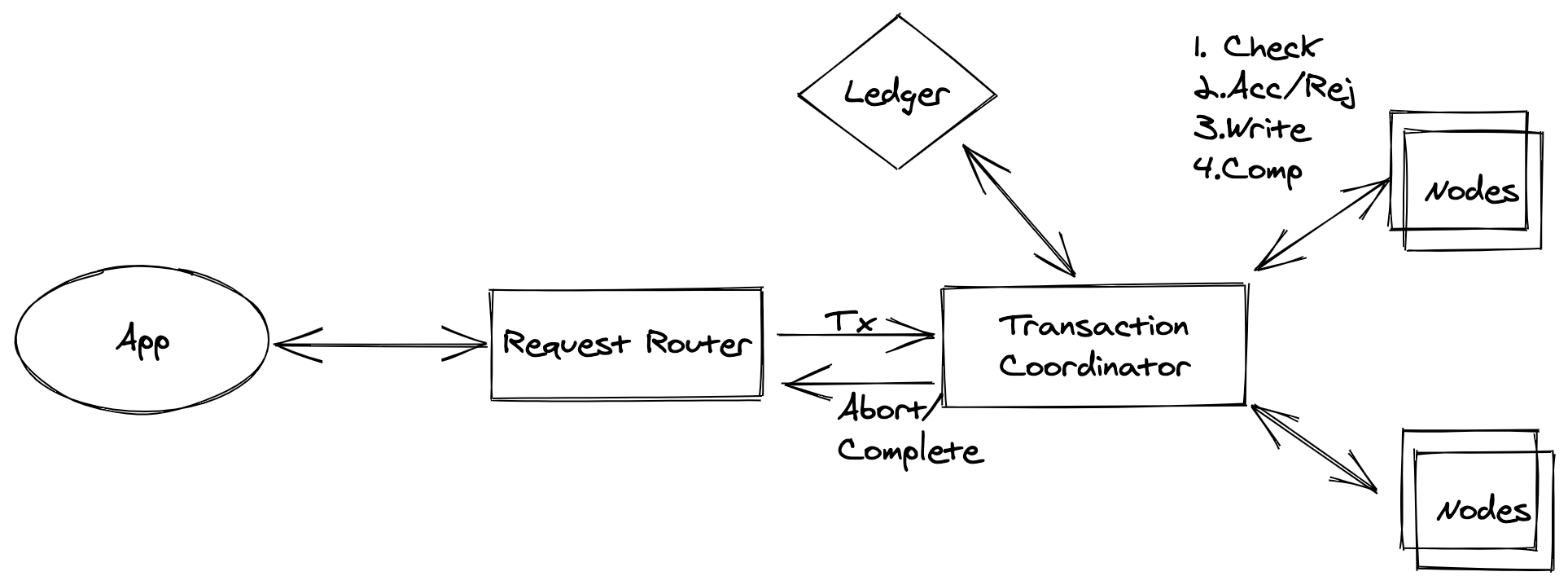
Since 2018, DynamoDB supports transactions. Though the transaction is not based on locks. It uses transaction coordinator to do the transaction just like 2PC for the items in that transaction. It also uses ledger to make the coordinator stateless which means it can be scaled easily.
The methodology is somehow like the deterministic database concept that DynamoDB uses timestamps to align and coordinate each transaction in a distributed storage even the transaction order is not aligned in each coordinator group.
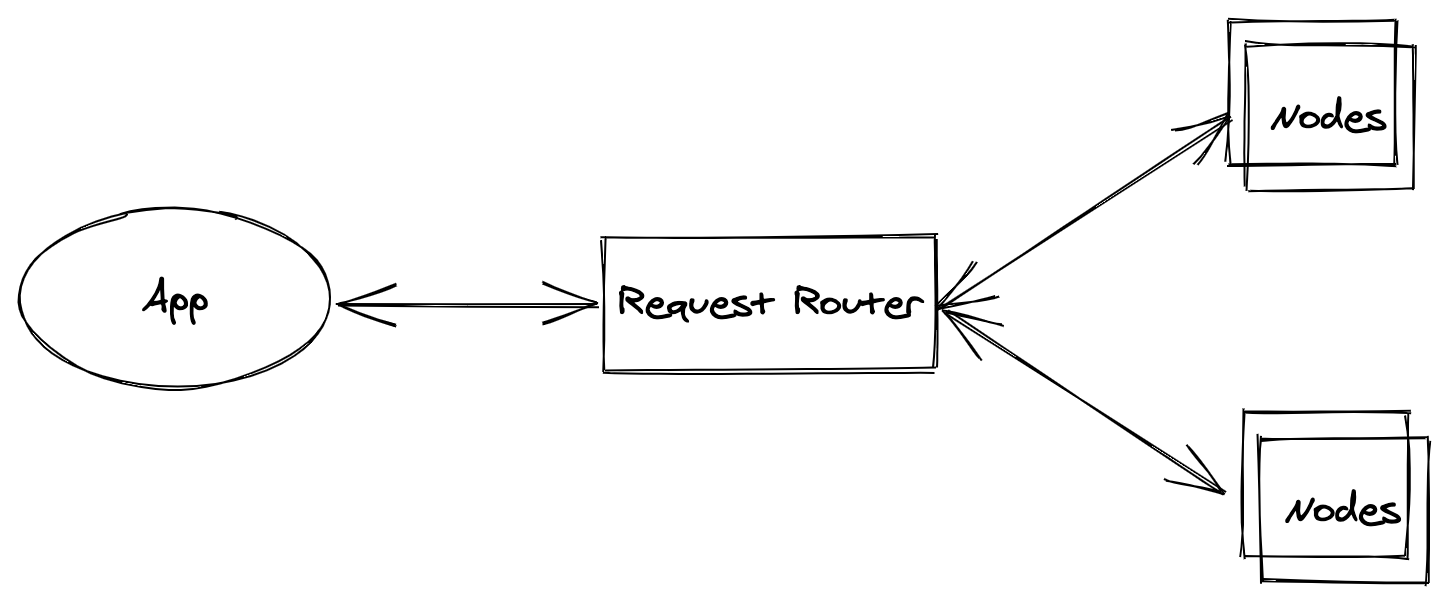
DynamoDB w/o Transaction
DynamoDB w Transaction
DynamoDB Mix
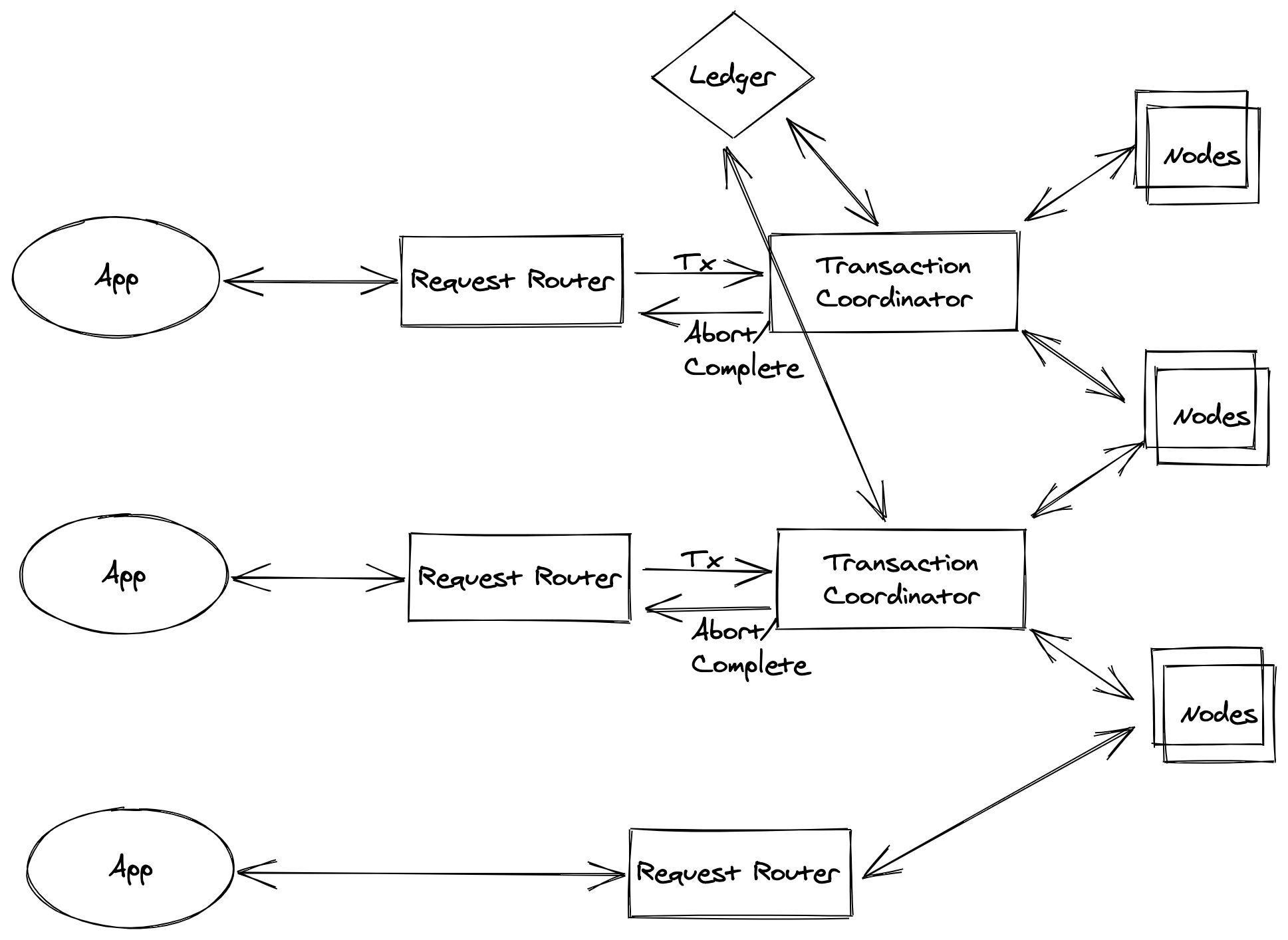
DynamoDB performs two underlying reads or writes of every item in the transaction: one to prepare the transaction and one to commit the transaction. The two underlying read/write operations are visible in your Amazon CloudWatch metrics.
Conclusion
DynamoDB is a popular NewSQL database which store items in a KV data model based on Gossip algorithm. It has two consistency models - eventually consistency and strong consistency, though neither of them can give the same consistency level as RDMS like MySQL or Postgres.
DynamoDB supports transactions since 2018, though it does not use locks or MVCC as the RDMS, instead it uses a timestamp-based transaction coordinator to do the transaction for scalability. Right now the transaction semantic only live in one region, hope it supports multi-region in the near future.