What are we talking about when we talk about transaction in a distributed system
Background
Cloud-Native and Microservice are getting popular in recent days. With the increase of business needs and stability requirements, we will have multi regions, multi datacenters, multi countries, even multi planets deployments for all kinds of features - security isolation, multi-tenant - that makes a distributed system.
In the traditional system, we are using RDMS like MySQL to support this requirement. The classic MySQL cluster is a primary-secondary architecture that has one active primary node for RW and several secondary nodes replicate from the primary.
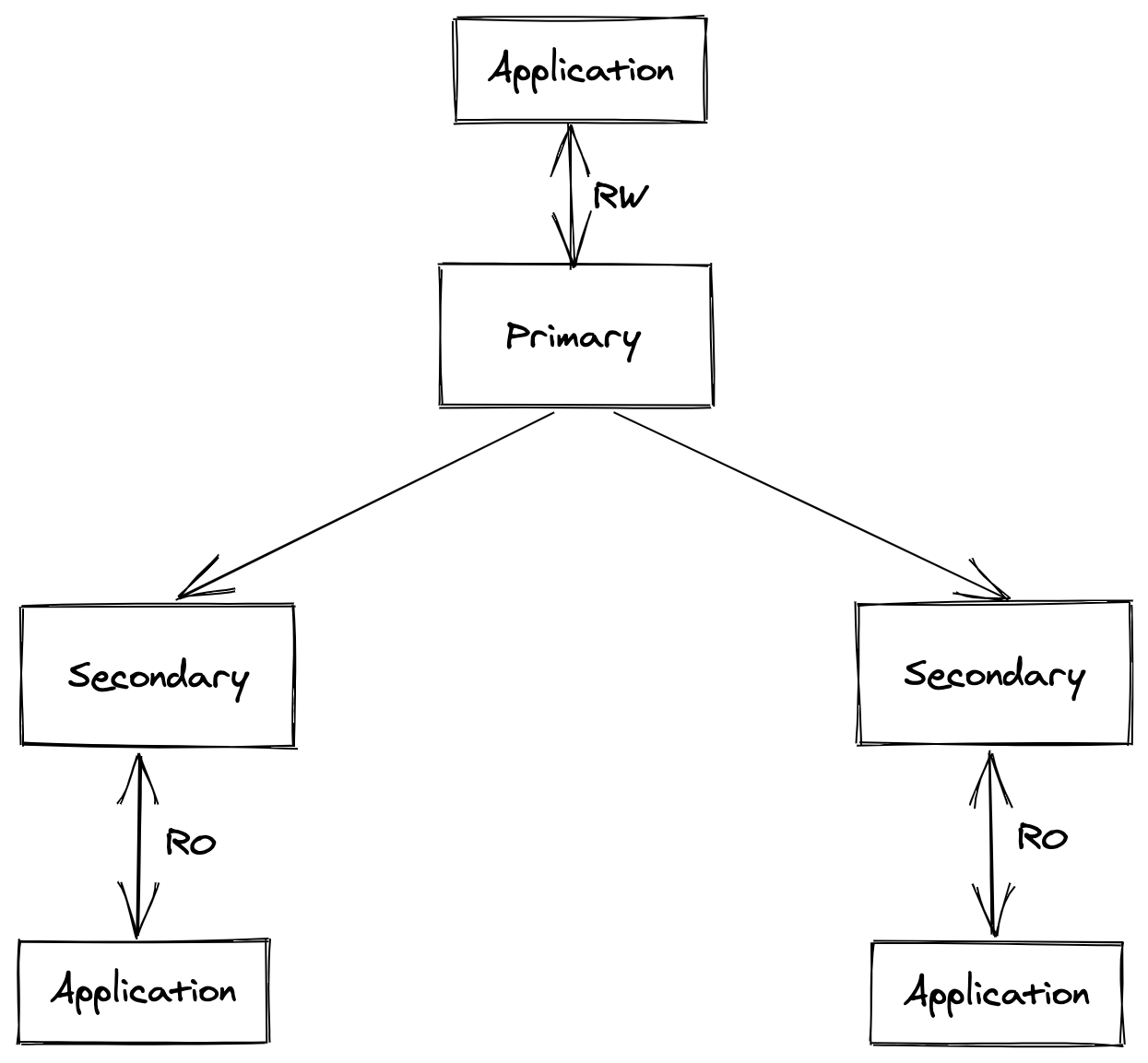
This centric architecture works well in a multi-region environment because the latency is low in one datacenter. Though with the service crossing multiple datacenters even continents, the latency from application to the primary becomes intolerable. The involvement of data storage is inevitable.
To solve the single primary issue, the architecture involved from central to distributed, there are tons of terms that emerged which some of them are confusing or overlap. Let's see some concepts and solutions in a real distributed system.
Transaction vs Consistency
Sometimes transaction and consistency are brought up together. But they are very different stuff in data storage.
Transaction
Transaction processing is information processing in computer science that is divided into individual, indivisible operations called transactions. Each transaction must succeed or fail as a complete unit; it can never be only partially complete.
Transaction is the term to describe the isolation for the storage, which reflects the serializability in a database like read uncommitted, read committed, repeatable read and snapshot, etc.
Transaction has NOTHING to do with the order of operations, which is a common misunderstanding.
| Level | Dirty Read | Nonrepeatable Read | Phantom Read |
|---|---|---|---|
| 0, Read uncommitted | Yes | Yes | Yes |
| 1, Read committed | No | Yes | Yes |
| 2, Repeatable read | No | No | Yes |
| 3, Serializable | No | No | No |
Consistency
The system is said to support a given model if operations on memory follow specific rules. The data consistency model specifies a contract between programmer and system, wherein the system guarantees that if the programmer follows the rules, memory will be consistent and the results of reading, writing, or updating memory will be predictable. Consistency deals with the ordering of operations to multiple locations with respect to all processors.
Consistency is the rules between each operation/transaction like time serials, relationship, and causality which reflect the linearizability in a database like linearizability, sequential, causal, etc.
Consistency describes the relationship between each operation, which is different from the transaction, and is hard.
Why?
Because we are living in a 4-dimension world!
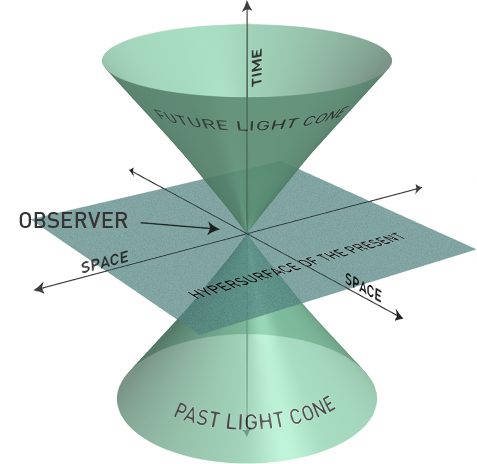
The world we can observe is just the cube in the current time point, no more no less. So is the database observability.
Every operation is not atomic literally - for instance, it takes:
- 1 nanosecond to reference a CPU's Level 1 cache
- 3 nanoseconds for a CPU branch mispredict (but let's not think about the security implications!)
- 100 nanoseconds to reference something in main memory
- 88 nanoseconds to send 2,000 bytes over a network
- 16,000 nanoseconds to read random information from a solid-state drive (an SSD)
- 150,000,000 nanoseconds to send a network packet from California to the Netherlands and receive a reply
That is the reason we have different consistency levels and sooooo many algorithms to restrict the consistency(will describe in the following chapter).
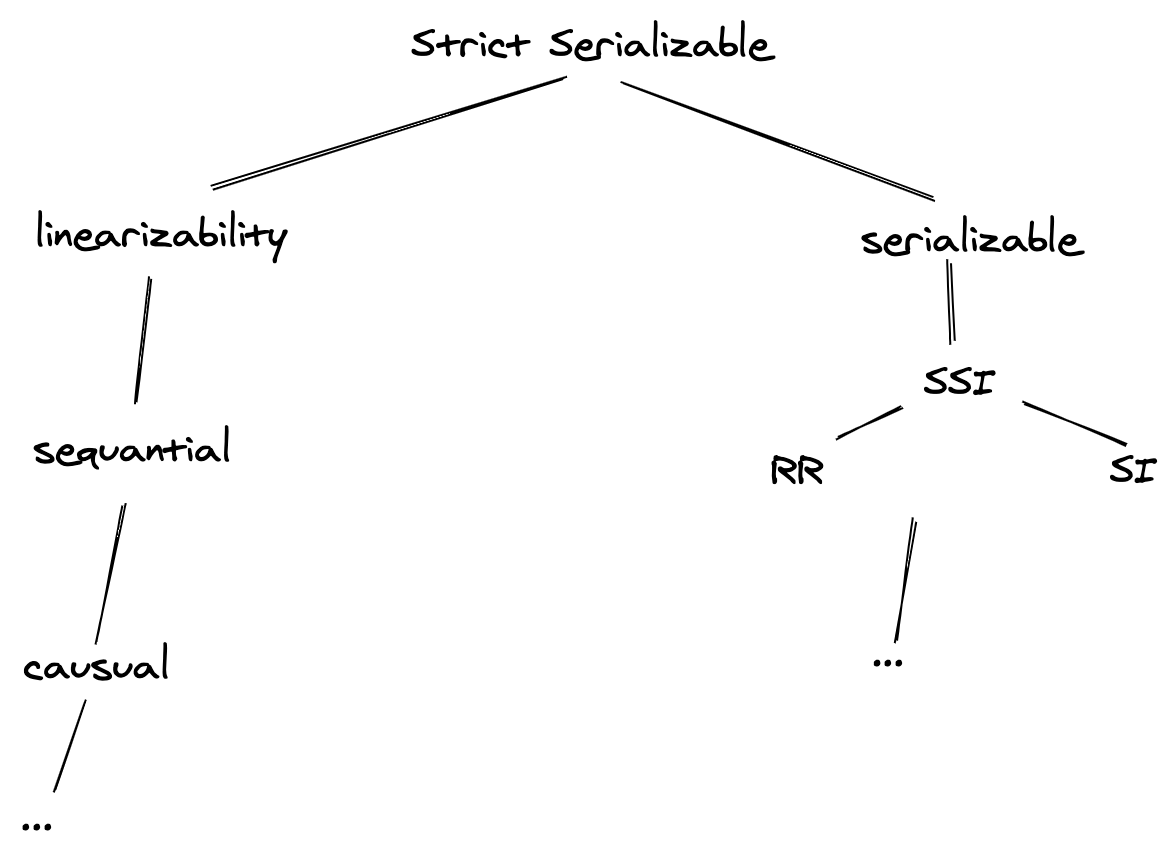
Strict Serializable
Strict Serializable is the term to describe the strongest restriction for both serializability and linearizability, which is linearizable + serializable.
Challenge in Distributed System
It is hard to handle the operations like a single database w/o performance penalty in a distributed system. That is the main reason we have two consistent models in a distributed system: ACID and BASE.
Data Consistency - ACID vs BASE
ACID Model
- Atomic – Each transaction is either properly carried out or the process halts and the database reverts back to the state before the transaction started. This ensures that all data in the database is valid.
- Consistent – A processed transaction will never endanger the structural integrity of the database.
- Isolated – Transactions cannot compromise the integrity of other transactions by interacting with them while they are still in progress.
- Durable – The data related to the completed transaction will persist even in the cases of network or power outages. If a transaction fails, it will not impact the manipulated data.
Database samples: MySQL, PostgreSQL, Oracle, SQLite, and Microsoft SQL Server, DB2.
BASE Model
- Basically Available – Rather than enforcing immediate consistency, BASE-modelled NoSQL databases will ensure availability of data by spreading and replicating it across the nodes of the database cluster.
- Soft State – Due to the lack of immediate consistency, data values may change over time. The BASE model breaks off with the concept of a database which enforces its own consistency, delegating that responsibility to developers.
- Eventually Consistent – The fact that BASE does not enforce immediate consistency does not mean that it never achieves it. However, until it does, data reads are still possible (even though they might not reflect the reality).
Database samples: MongoDB, Cassandra, Redis, Couchbase, DynamoDB.
Solution in Distributed System
There are two methods to make a distributed system robust - partition and replication. Partition makes it scalable and responsive, replication makes it stable and fault-tolerant. Though that makes it even harder to keep the system transactional and consistent.
There are a lot of mature papers about consistent in a distributed system, like Paxos, Raft, Zab for ACID and GOSSIP for BASE, etc.
For transactions, the traditional way is using the lock, like Percolator. Though with the physical devices help, the paper Spanner gives a new solution for a worldwide transaction guarantee w/ acceptable performance. Though the performance and implementation effort are still considerable. There have other approaches like CalvinDB, though still has a gap from theory to industry.
Usage: OLTP vs OLAP
OLTP
In Online transaction processing (OLTP), information systems typically facilitate and manage transaction-oriented applications.
The term "transaction" can have two different meanings, both of which might apply: in the realm of computers or database transactions it denotes an atomic change of state, whereas in the realm of business or finance, the term typically denotes an exchange of economic entities (as used by, e.g., Transaction Processing Performance Council or commercial transactions.):50 OLTP may use transactions of the first type to record transactions of the second.
OLAP
Online analytical processing, or OLAP, is an approach to answer multi-dimensional analytical (MDA) queries swiftly in computing. OLAP is part of the broader category of business intelligence, which also encompasses relational databases, report writing and data mining. Typical applications of OLAP include business reporting for sales, marketing, management reporting, business process management (BPM), budgeting and forecasting, financial reporting and similar areas, with new applications emerging, such as agriculture.
Can I Have BOTH? - HTAP
Hybrid transaction/analytical processing (HTAP), a term created by Gartner Inc. – an information technology research and advisory company. As defined by Gartner:
Hybrid transaction/analytical processing (HTAP) is an emerging application architecture that "breaks the wall" between transaction processing and analytics. It enables more informed and "in business real time" decision making.
Database sample: CockroachDB, TiDB, Spanner.
HTAP in databases is kind of like iPhone in cellphones. It is a trade-off between excellence and capability(for the recently new-SQL database, it is excellent too). For 90% of cases, the new-SQL database is enough, for the other 10% of cases, the traditional database cannot work either lol. Meanwhile, HTAP new-SQL is so friendly to the user that just like an iPhone.
Next Stop - CRDT?
In distributed computing, a conflict-free replicated data type (CRDT) is a data structure which can be replicated across multiple computers in a network, where the replicas can be updated independently and concurrently without coordination between the replicas, and where it is always mathematically possible to resolve inconsistencies that might come up.
There are multiple CRDT algorithms for different structures like text, list, tree, etc., it is very important to choose the different approaches for different scenarios.