聊聊DynamoDB的一致性
开始
DynamoDB 在 AWS 家族中非常流行。每个没用 DynamoDB 的人都想用它,每个正在用 DynamoDB 的人都想抛弃它 :p
让我们来看看 DynamoDB 能做什么、不能做什么,以及以前不能做但现在能做的事情。
ACID vs BASE
ACID 模型广泛应用于关系型数据库中。它为数据库提供强序列化保证,使得数据库对应用程序而言表现为一个整体。
相比 ACID,BASE 模型是在一致性与应用程序所关心的其他方面(如可用性、数据格式或延迟)之间做出的权衡。这意味着应用程序需要处理或忽略一致性的降级,以换取某些方面的提升。
ACID 模型
- 原子性(Atomic)– 每个事务要么被正确执行,要么中止并将数据库恢复到事务开始前的状态。这确保了数据库中所有数据的有效性。
- 一致性(Consistent)– 已处理的事务永远不会破坏数据库的结构完整性。
- 隔离性(Isolated)– 事务在进行过程中不会因与其他事务的交互而损害其他事务的完整性。
- 持久性(Durable)– 与已完成事务相关的数据即使在网络或电源中断的情况下也会持久保存。如果事务失败,不会影响已操作的数据。
数据库示例:MySQL、PostgreSQL、Oracle、SQLite、Microsoft SQL Server、DB2。
BASE 模型
- 基本可用(Basically Available)– BASE 模型的 NoSQL 数据库不强制即时一致性,而是通过在数据库集群的各节点之间分散和复制数据来确保数据的可用性。
- 软状态(Soft State)– 由于缺乏即时一致性,数据值可能随时间变化。BASE 模型放弃了由数据库自身强制一致性的概念,将这一责任委托给开发者。
- 最终一致性(Eventually Consistent)– BASE 不强制即时一致性并不意味着永远无法达到一致。但在达到一致之前,数据读取仍然是可能的(即使读取结果可能不反映最新状态)。
数据库示例:MongoDB、Cassandra、Redis、Couchbase、DynamoDB。
DynamoDB 数据模型
DynamoDB 是键值存储,不过与 Redis 等其他键值存储略有不同。
从对比的角度来看,Amazon DynamoDB 中的一行被称为一个 item(项),每个项可以有任意数量的 attributes(属性)。属性由键和值组成,通常被称为名称-值对。Amazon DynamoDB 表可以有无限数量的项,通过主键进行索引。
Amazon DynamoDB 定义了两种类型的主键:一种是只有一个属性(称为分区键)的简单主键,另一种是包含两个属性的复合主键。主键是用于一致性哈希的哈希键。复合键用于在指定分区节点中进行查询。除了键之外,DynamoDB 还支持索引。整体数据模型类似于 Cassandra(除了 Cassandra 使用列族模型),在细节上有所不同。
基于这种数据模型,DynamoDB 是一个真正的分布式 NoSQL 数据库,与 MySQL 等只有单一主存储的关系型数据库不同。关于 DynamoDB 数据模型的更多细节可以参考这里。
DynamoDB 一致性模型
从前面的章节中,我们知道 DynamoDB 中的数据被分割到各个分区中。现在让我们来讨论 DynamoDB 的一致性模型。
由于 DynamoDB 是一个黑盒,大部分关于 AWS 产品的信息来自论文或测试。简而言之,DynamoDB 是一个符合 BASE 模型的最终一致性 NoSQL 数据库,不过根据 AWS 文档,它也可以实现强一致性。那么什么是强一致性?它和 RDMS 中的序列化是一样的吗?
要回答这个问题,首先我们需要了解分布式系统中的序列化模型。
为什么在分布式数据库中一致性如此困难?
要回答这个问题,我们需要先理解序列化模型。我们不会讲得太深,因为彻底弄清楚可能需要好几天。相反,我们只会在分布式数据库的语境下揭开这个概念的面纱,以便我们具备回答问题的基本理解。
当我们在传统 RDMS 中谈论事务时,我们通常假设事务保证了 ACID。实际上并非如此。事务与一致性无关,而是关于原子性和隔离性。
一致性确保事务只能将数据库从一个有效状态带到另一个有效状态,它保证在任何给定时间点的状态集合都是有效的。
让我们回到序列化模型。
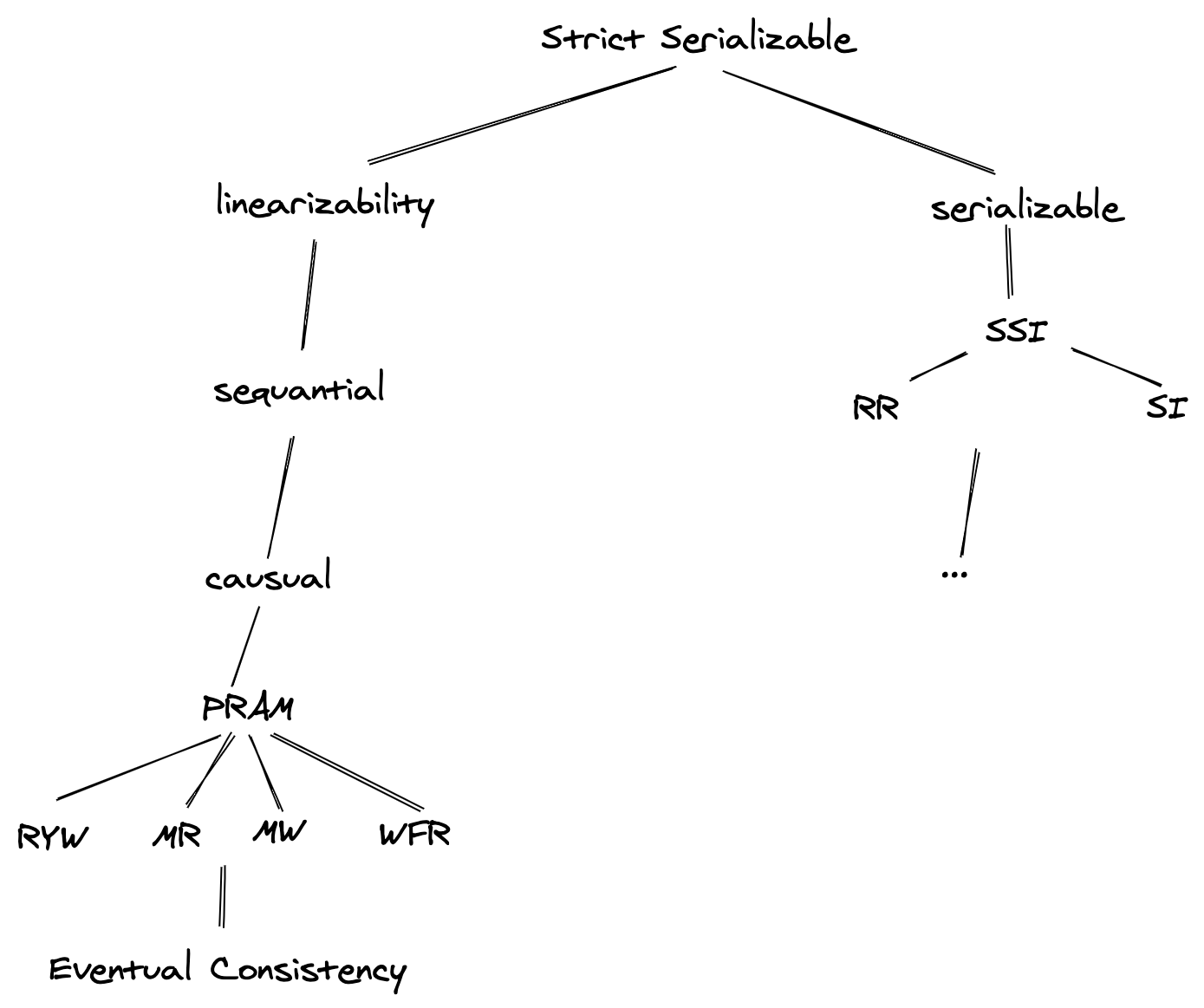
从上图中可以看到,强序列化来自树的两个部分:右侧部分是序列化模型,类似于我们在数据库中熟悉的隔离级别。左侧部分是一致性级别,在传统数据库中,我们使用一些方法如锁或时间点视图(如乐观锁/悲观锁、MVCC 等)。这些方法在 MySQL 等传统 RDMS 中被广泛使用,但在 DynamoDB 等 NewSQL 中却没有使用,为什么?
因为代价太大了。无论 RDMS 中使用哪种一致性算法,总是需要锁,不管锁的类型是什么。与单一主节点相比,分布式系统中维护锁的代价是巨大的,像 2PC 这样的算法无法扩展,那就失去了分布式系统的意义。
但是等等!DynamoDB 提供了最终一致性和强一致性。DynamoDB 的强一致性和 RDMS 的一致性是一样的吗?现在让我们来看看 DynamoDB 中的一致性级别。
DynamoDB 中的一致性
DynamoDB 使用 Gossip 分布式算法来实现最终一致性,相关论文可以在这里找到。该算法使用 quorum 来实现灵活的一致性模型。
quorum 是分布式事务为了被允许在分布式系统中执行操作而必须获得的最小投票数。基于 quorum 的技术被用来在分布式系统中强制实现一致的操作。
在 DynamoDB 的强一致性中,它意味着 Rr + Wr > Tr,其中 Rr 表示读副本因子,Wr 表示写副本因子,Tr 表示总副本因子。这个公式很简单,确保大多数节点对每个操作有一致的响应。通常 Rr = Wr = Tr/2 + 1。
注意:论文中使用 Vector Clock 作为每个项的时间戳,但在实际实现中,由于性能问题被 Last Write Wins(LWW)所取代。DynamoDB 全局表也使用 LWW。根据这篇文章,单区域内的 DynamoDB 可能也使用 LWW。
Quorum 与隔离性?
如上所述,quorum 是一种一致性模型,与隔离性无关。它只适用于单个项。
Quorum 与一致性?
quorum 模型能映射到 RDMS 中的顺序一致性吗?答案是——不能。基于一致性模型的概念,顺序模型中的读操作应该获取到在它之前发生的最新写入。因果模型也是如此。
强一致性模型属于会话保证(Session Guarantees),它确保一致性在指定会话中是顺序的——
- 读己之写(Read Your Writes):如果一个进程执行了写操作,同一进程随后能观察到其写入的结果。
- 单调读(Monotonic Reads):一个进程观察(读取)到的写入集合保证是单调非递减的。
- 单调写(Monotonic Writes):如果某个进程先执行一次写操作,稍后再执行另一次写操作,其他进程将以相同的顺序观察到它们。
- 写跟随读(Write Follow Reads)- 尊重因果性:如果某个进程先执行读操作后执行写操作,而另一个进程观察到了写操作的结果,那么它也能观察到该读操作(除非已被覆写)。
彩蛋 - DynamoDB 事务
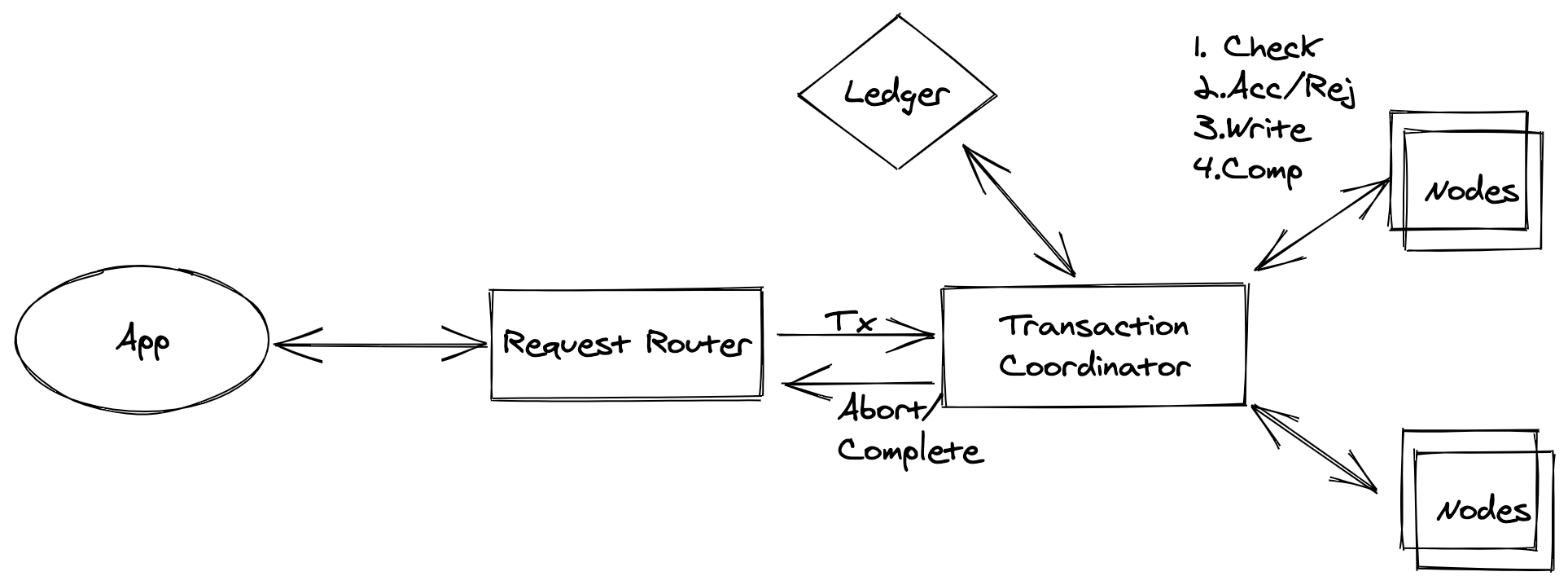
自 2018 年起,DynamoDB 支持事务。不过该事务并非基于锁实现。它使用事务协调器(transaction coordinator)来执行事务,类似于对事务中各项执行 2PC。它还使用 ledger 来使协调器无状态化,这意味着它可以轻松扩展。
其方法论在某种程度上类似于确定性数据库的概念——DynamoDB 使用时间戳来对齐和协调分布式存储中的每个事务,即使事务顺序在各协调器组中并不对齐。
无事务的 DynamoDB
有事务的 DynamoDB
DynamoDB 混合模式
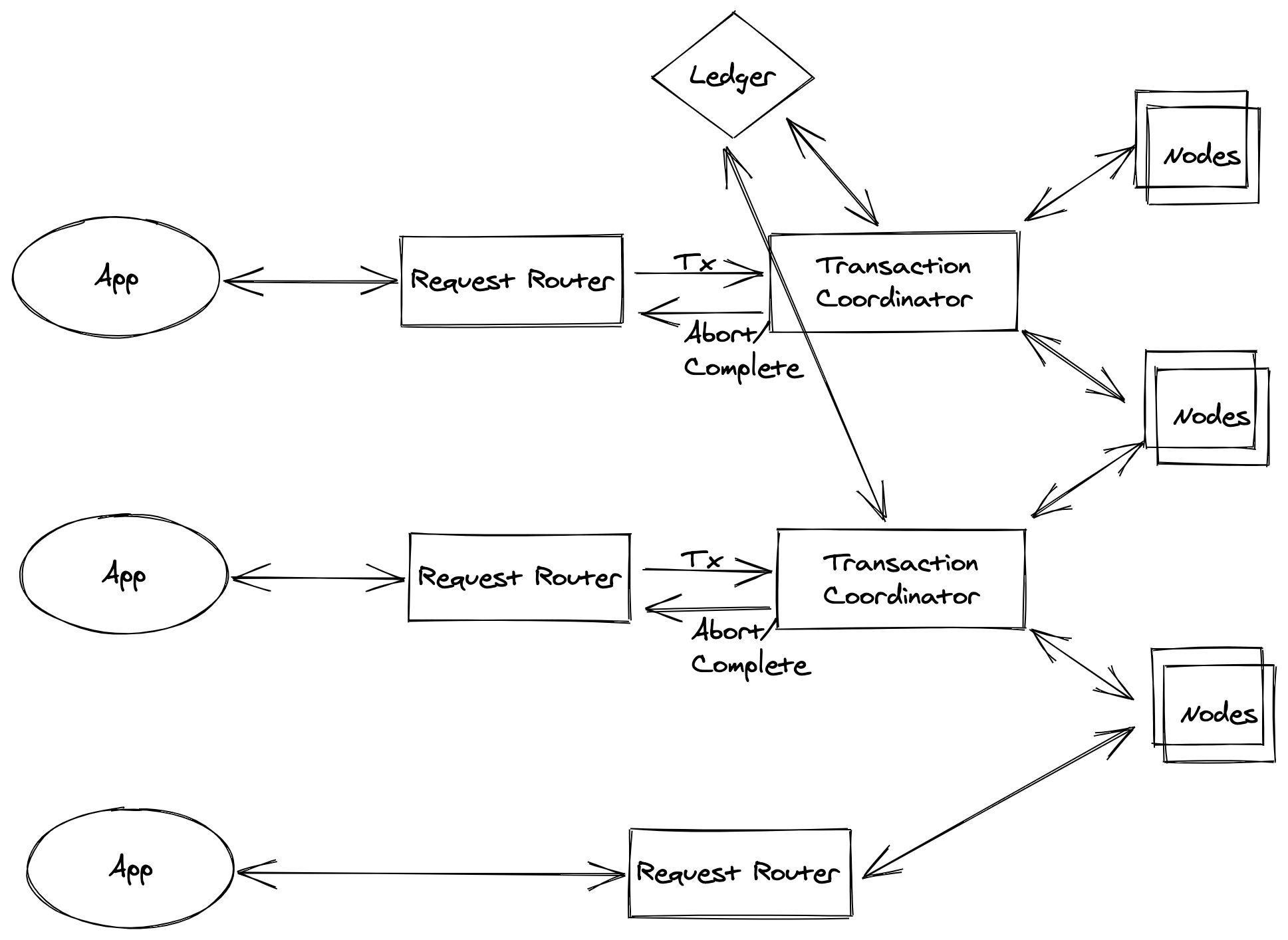
DynamoDB 对事务中的每个项执行两次底层读或写操作:一次用于准备事务,一次用于提交事务。这两次底层读/写操作在你的 Amazon CloudWatch 指标中是可见的。
总结
DynamoDB 是一个流行的 NewSQL 数据库,基于 Gossip 算法以键值数据模型存储项。它有两种一致性模型——最终一致性和强一致性,但两者都无法提供与 MySQL 或 PostgreSQL 等 RDMS 相同级别的一致性。
DynamoDB 自 2018 年起支持事务,但它不像 RDMS 那样使用锁或 MVCC,而是使用基于时间戳的事务协调器来执行事务以实现可扩展性。目前事务语义仅在单区域内有效,希望未来能支持多区域。