聊聊分布式系统中的事务
背景
云原生和微服务在近年来越来越流行。随着业务需求和稳定性要求的不断增长,我们需要在多区域、多数据中心、多国家甚至多星球部署各种功能——安全隔离、多租户——这就构成了分布式系统。
在传统系统中,我们使用像 MySQL 这样的关系型数据库来支撑这些需求。经典的 MySQL 集群是一主多从的架构,有一个活跃的主节点负责读写,多个从节点从主节点复制数据。
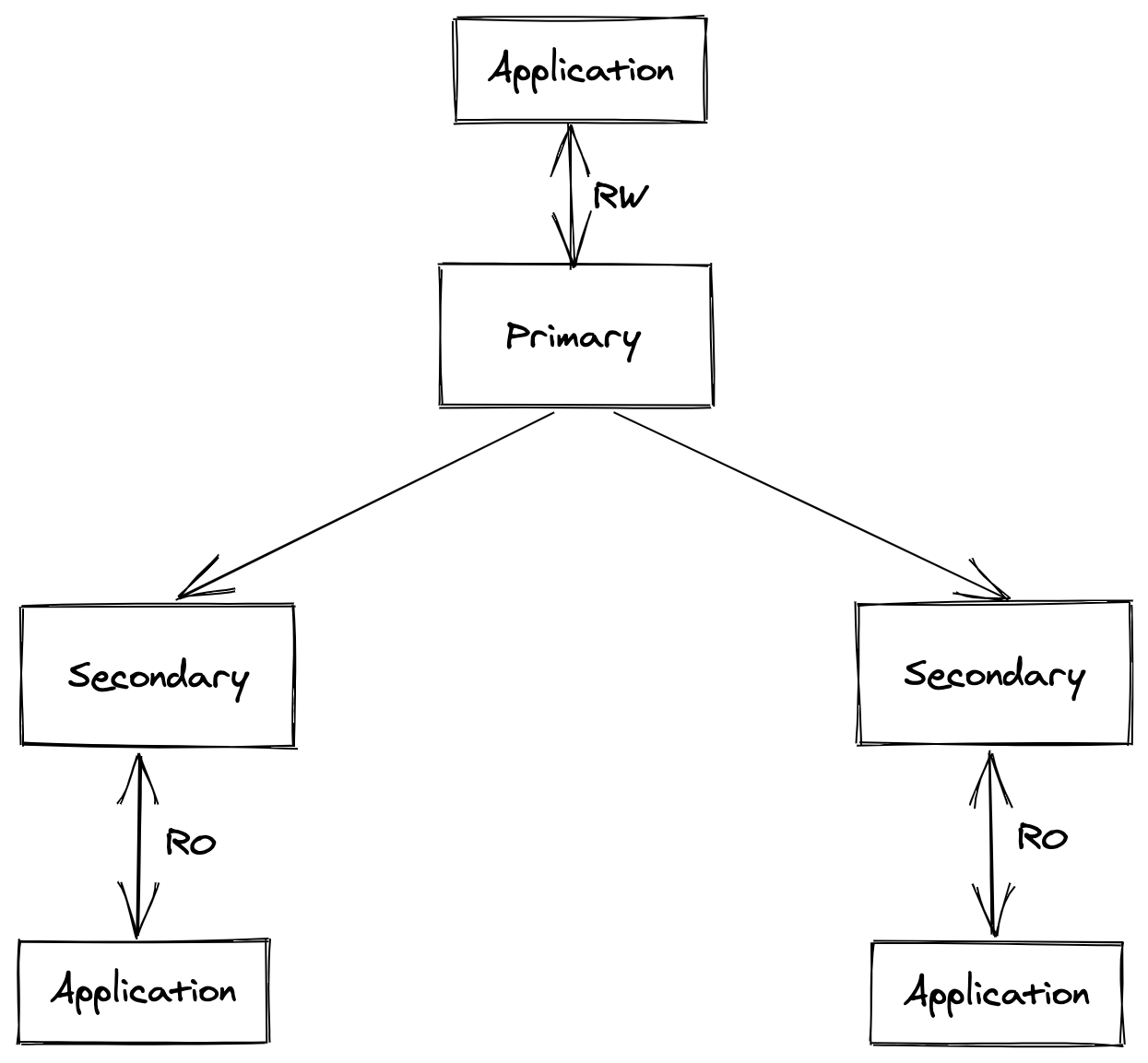
这种中心化架构在单一数据中心的多区域环境下表现良好,因为延迟较低。然而当服务跨越多个数据中心甚至大洲时,应用到主节点的延迟就变得不可忍受了。数据存储层的演进不可避免。
为了解决单主节点的问题,架构从中心化演进为分布式,涌现出大量术语,其中一些容易混淆或存在交叉重叠。让我们来看看真实分布式系统中的一些概念和解决方案。
事务 vs 一致性
事务和一致性经常被放在一起讨论,但它们在数据存储中是完全不同的概念。
事务(Transaction)
事务处理是计算机科学中的一种信息处理方式,将操作划分为不可分割的独立单元,称为事务。每个事务必须作为一个完整的单元要么成功要么失败,永远不会只完成一部分。
事务是描述存储隔离性的术语,体现为数据库中的可串行化(serializability),如读未提交、读已提交、可重复读和快照隔离等。
事务与操作的顺序没有任何关系,这是一个常见的误解。
| Level | Dirty Read | Nonrepeatable Read | Phantom Read |
|---|---|---|---|
| 0, Read uncommitted | Yes | Yes | Yes |
| 1, Read committed | No | Yes | Yes |
| 2, Repeatable read | No | No | Yes |
| 3, Serializable | No | No | No |
一致性(Consistency)
如果对内存的操作遵循特定规则,则称系统支持给定的模型。数据一致性模型规定了程序员与系统之间的契约,系统保证如果程序员遵循规则,内存将保持一致,读取、写入或更新内存的结果将是可预测的。一致性处理的是所有处理器对多个位置的操作顺序。
一致性是描述每个操作/事务之间的规则,如时间序列、关系和因果性,体现为数据库中的线性一致性(linearizability),如线性一致性、顺序一致性、因果一致性等。
一致性描述的是每个操作之间的关系,与事务不同,而且很难实现。
为什么?
因为我们生活在一个四维世界中!
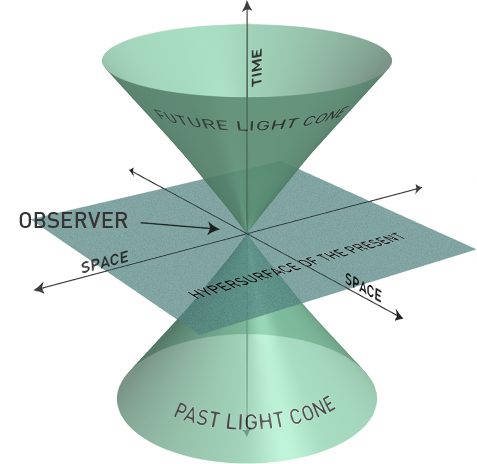
我们能观测到的世界仅仅是当前时间点的那个立方体,不多也不少。数据库的可观测性也是如此。
每个操作从物理层面来说都不是真正原子的——例如:
- 引用 CPU 一级缓存需要 1 纳秒
- CPU 分支预测失败需要 3 纳秒(但我们先不考虑安全隐患!)
- 引用主存需要 100 纳秒
- 通过网络发送 2,000 字节需要 88 纳秒
- 从固态硬盘(SSD)随机读取数据需要 16,000 纳秒
- 从加利福尼亚发送网络包到荷兰并收到回复需要 150,000,000 纳秒
这就是为什么我们有不同的一致性级别和各种各样的算法来约束一致性(将在后续章节中描述)。
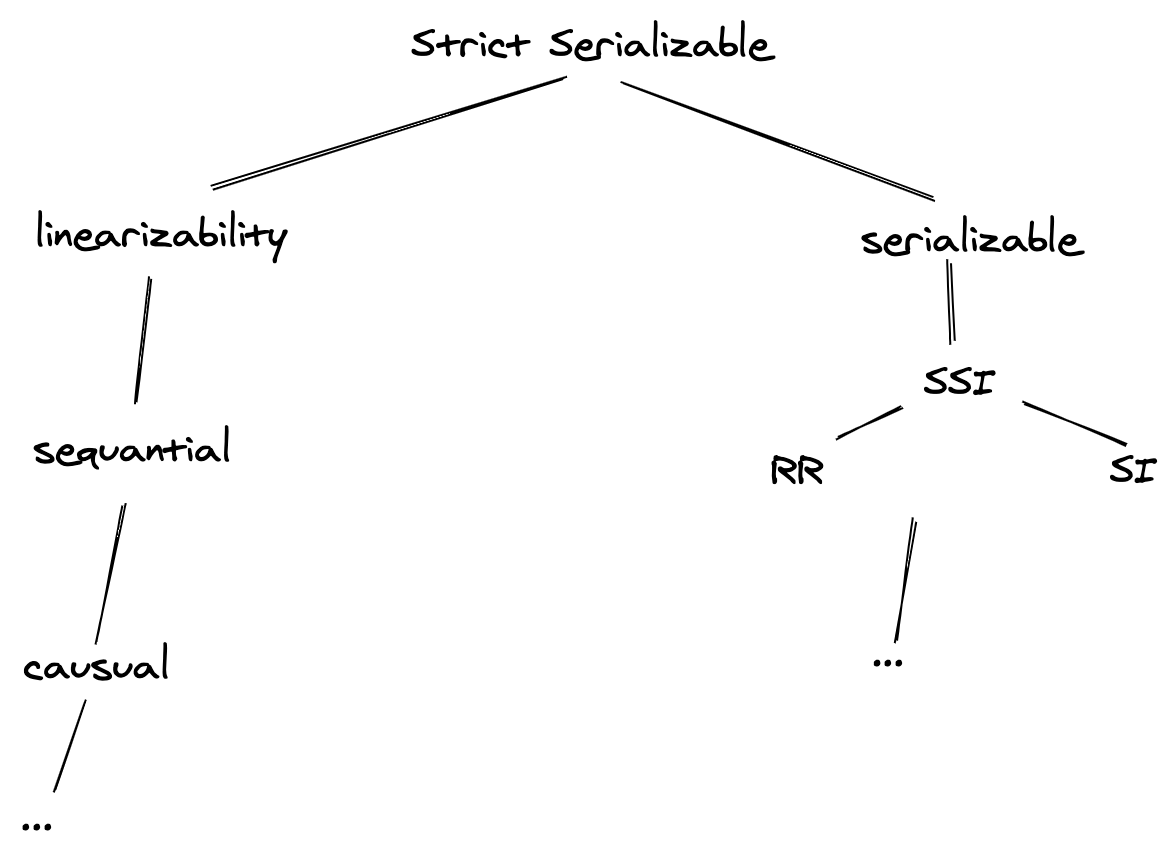
严格可串行化(Strict Serializable)
严格可串行化是描述对可串行化和线性一致性最强约束的术语,即线性一致性 + 可串行化。
分布式系统中的挑战
在分布式系统中,要像单一数据库那样处理操作且不产生性能损耗是非常困难的。这也是分布式系统中存在两种一致性模型的主要原因:ACID 和 BASE。
数据一致性 - ACID vs BASE
ACID 模型
- 原子性(Atomic)– 每个事务要么被正确执行,要么整个过程停止并将数据库恢复到事务开始之前的状态。这确保了数据库中所有数据的有效性。
- 一致性(Consistent)– 已处理的事务永远不会破坏数据库的结构完整性。
- 隔离性(Isolated)– 事务在执行过程中不会因为与其他未完成的事务交互而损害其完整性。
- 持久性(Durable)– 已完成事务的相关数据即使在网络或电源中断的情况下也会持久保存。如果事务失败,它不会影响已操作的数据。
数据库示例:MySQL、PostgreSQL、Oracle、SQLite、Microsoft SQL Server、DB2。
BASE 模型
- 基本可用(Basically Available)– BASE 模型的 NoSQL 数据库不强制即时一致性,而是通过在数据库集群的节点间分散和复制数据来确保数据可用性。
- 软状态(Soft State)– 由于缺乏即时一致性,数据值可能随时间变化。BASE 模型打破了数据库自身强制一致性的概念,将这一责任委托给开发者。
- 最终一致性(Eventually Consistent)– BASE 不强制即时一致性并不意味着它永远达不到一致性。只是在达到一致之前,数据读取仍然是可能的(尽管读到的可能不反映最新状态)。
数据库示例:MongoDB、Cassandra、Redis、Couchbase、DynamoDB。
分布式系统中的解决方案
使分布式系统健壮有两种方法——分区和复制。分区使其可扩展且响应迅速,复制使其稳定且具有容错能力。但这也使得保持系统的事务性和一致性变得更加困难。
关于分布式系统一致性,有很多成熟的论文,如用于 ACID 的 Paxos、Raft、Zab 以及用于 BASE 的 GOSSIP 等。
对于事务,传统方式是使用锁,如 Percolator。而借助物理设备的帮助,Spanner 论文为全球范围的事务保证提供了一种在可接受性能下的新解决方案。尽管性能和实现成本仍然相当可观。还有其他方案如 CalvinDB,但从理论到工业界仍有一定差距。
使用场景:OLTP vs OLAP
OLTP
在联机事务处理(OLTP)中,信息系统通常用于促进和管理面向事务的应用程序。
"事务"一词可能有两种不同的含义,且两者都可能适用:在计算机或数据库事务的领域中,它表示状态的原子变化;而在商业或金融领域中,该术语通常表示经济实体之间的交换(例如事务处理性能委员会或商业事务所使用的含义)。OLTP 可能使用第一种类型的事务来记录第二种类型的事务。
OLAP
联机分析处理(OLAP)是一种在计算中快速回答多维分析(MDA)查询的方法。OLAP 是商业智能这一更广泛类别的一部分,该类别还包括关系数据库、报表编写和数据挖掘。OLAP 的典型应用包括销售、营销、管理报告、业务流程管理(BPM)、预算和预测、财务报告等类似领域的商业报告,同时也在不断涌现新的应用场景,如农业。
能否兼得?- HTAP
混合事务/分析处理(HTAP)是由 Gartner 公司——一家信息技术研究和咨询公司——创造的术语。Gartner 对其定义如下:
混合事务/分析处理(HTAP)是一种新兴的应用架构,它"打破了"事务处理和分析之间的壁垒。它能够实现更加知情的、"业务实时"的决策制定。
数据库示例:CockroachDB、TiDB、Spanner。
HTAP 数据库之于数据库,就像 iPhone 之于手机。它是在卓越性和能力之间的权衡(对于近年来的 NewSQL 数据库,它同样表现出色)。对于 90% 的场景,NewSQL 数据库已经足够;而对于另外 10% 的场景,传统数据库同样无法胜任(笑)。同时,HTAP NewSQL 对用户极其友好,就像 iPhone 一样。
下一站 - CRDT?
在分布式计算中,无冲突复制数据类型(CRDT)是一种可以在网络中的多台计算机之间复制的数据结构,其中副本可以独立且并发地更新而无需副本之间的协调,并且在数学上始终可以解决可能出现的不一致性。
针对不同的数据结构如文本、列表、树等,存在多种 CRDT 算法,针对不同场景选择合适的方案非常重要。